

Showing Query Description in Infobox
Knowledge Graph is used to give a brief introduction about the search query instantly. But the information of knowledge graph becomes more useful when it is defined by one or two line description. Google currently shows a description of search query in its knowledge graph which makes the search results more meaningful. In this blog I will describe how I have description for query using Wikidata API implemented a similar functionality in Susper.
Steps:
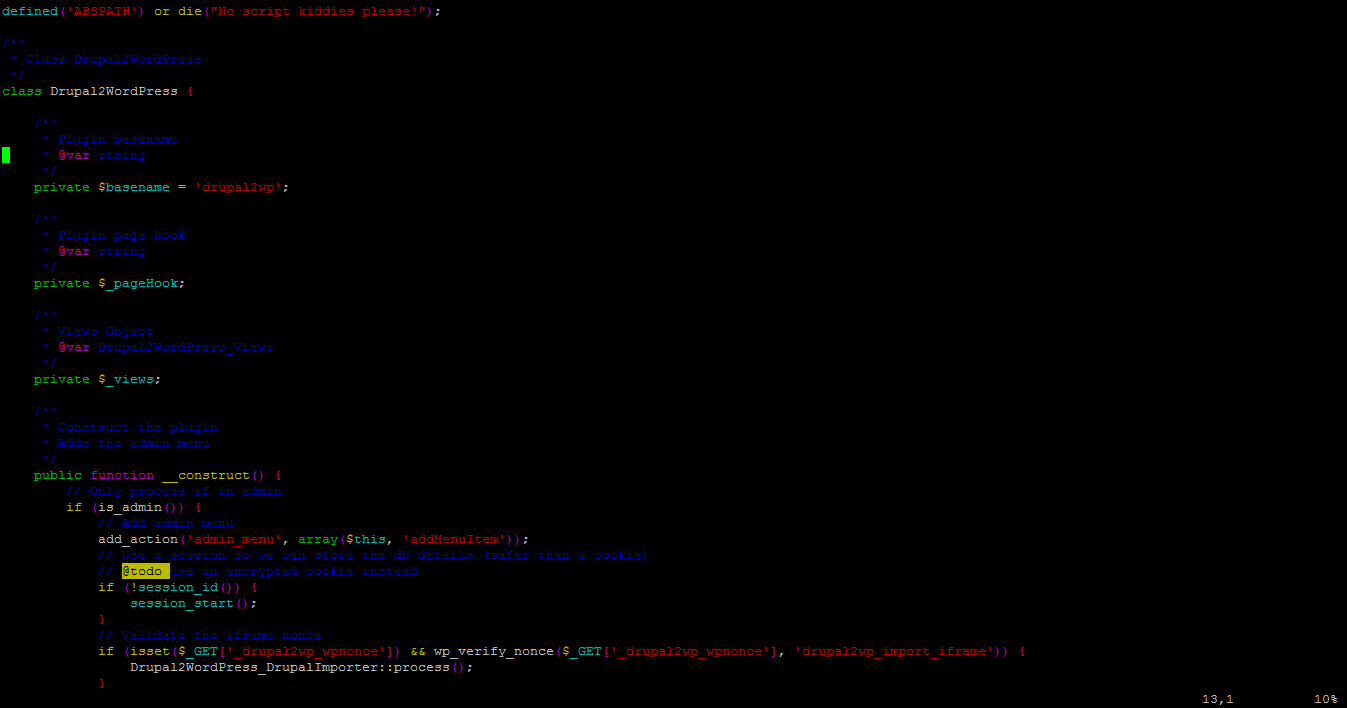
1.Adding a function to fetch data from Wikidata in Service:
getQueryDescription(searchquery) {
const params = new URLSearchParams();
params.set('origin', '*');
params.set('action', 'wbsearchentities');
params.set('search', searchquery);
params.set('language', 'en');
params.set('format', 'json');
const headers = new Headers({ 'Accept': 'application/json' });
const options = new RequestOptions({ headers: headers, search: params });
return this.http.get(this.descriptionURL, options).map(res =>
res.json()
).catch(this.handleError);
}
2.Creating an effect for query description:
To implement the logic of getting query description from the results returned by the service is made in knowledge.ts file which creates an effect for knowledge description.
Here is the effect for query description
this.knowledgeservice.getQueryDescription(querypay.query) .takeUntil(nextSearch$) .subscribe((response) => { if (response['search']) { this.store.dispatch(new knowledge.DescriptionAction(response)); return empty(); } else { this.store.dispatch(new knowledge.DescriptionAction([])); return empty(); } });
The response is then dispatched to the corresponding knowledge action.
3.Creating an Action for Query description:
After dispatching the query description logic to the action, we must have an action which will correspond to get the query description. Here is the implementation of Query Description Action in knowledge.ts action file.
export const ActionTypes = { CONTENT_CHANGE: type('[Knowledge] Content Change'), IMAGE_CHANGE: type('[Knowledge] Image Change'), DESCRIPTION_CHANGE: type('[Knowledge] Description Change') }; export class SearchContentAction implements Action { type = ActionTypes.CONTENT_CHANGE; constructor(public payload: object) {} } export class SearchImageAction implements Action { type = ActionTypes.IMAGE_CHANGE; constructor(public payload: object) {} } export class DescriptionAction implements Action { type = ActionTypes.DESCRIPTION_CHANGE; constructor(public payload: object) {} } export type Actions = SearchContentAction | SearchImageAction | DescriptionAction;
DescriptionAction is the action for Query Description and is then exported for the reducer.
4.Creating a case for query description in Knowledge reducer:
We must have a case to deal in reducer function to deal with query description action and here is the code for the case:
case knowledge.ActionTypes.DESCRIPTION_CHANGE: { const description_response = action.payload; return Object.assign({}, state, { content_response: state.content_response, image_response: state.image_response, description_response: description_response }); }
The new state is then exported to the store:
export const getDescriptionResponse = (state: State) => state.description_response;
5.Updating the contents in store:
To update the store we just retrieve the getKnowledgeState and read its description_response and export it.
export const getDescriptionResponse = (state: State) => state.description_response;
6.Fetching Query Description from store in infobox component:
Now fetching results is very simple, we just need to select the getDescription from the store at store it in description_response$ and then we extract the query description and store in a local variable querydescription
this.description_response$ = store.select(fromRoot.getDescription); this.description_response$.subscribe(res => { if (res['search']) { this.querydescription = res['search'][0]['description']; } } );
7.Displaying query description on the result page:
Now displaying the query description on our page is very simple we just need to use our querydescription variable.
<p class="query_description">{{this.querydescription}}</p><hr width="50%" align="left" *ngIf="this.image">
Resources
- Wikidata API: https://www.wikidata.org/w/api.php
- Angular Services: https://angular.io/tutorial/toh-pt4
- Corresponding Pull Request: https://github.com/fossasia/susper.com/pull/1115












You must be logged in to post a comment.