
Pike
(ˢᵒᶜⁱᵉᵗʸserver) aims to be a platform for developing collaborative applications.
sTeam server project repository: sTeam.
sTeam-REST API repository: sTeam-REST
The project is written in Pike programming language. Many of us would not be aware of it. Let’s take a dive into Pike and learn more about it.
What is pike?
Pike is a general purpose programming language, which means that you can put it to use for almost any task. Its application domain spans anything from the world of the Net to the world of multimedia applications, or environments where your shell could use some spicy text processing or system administration tools. Your imagination sets the limit, but Pike will probably extend it far beyond what you previously considered within reach. Pike is a dynamic programming language with a syntax similar to Java and C. It is simple to learn, does not require long compilation passes and has powerful built-in data types allowing simple and really fast data manipulation. Pike is released under the GNU GPL, GNU LGPL and MPL; this means that you can fetch it and use it for almost any purpose you please.
Who made pike?
We will not bother you here with the entire history of Pike, but in a quick summary we should credit Fredrik Hübinette, who started writing Pike (at that time called µLPC), Roxen Internet Software, who funded the Pike development during its first years, the Pike development team that continues its development at present and the Software and Systems division of the Department of Computer and Information Science (IDA for short) at Linköping University, who currently provides funding for some Pike research and development, as well as this site. Also, without the participation of the friendly community of Pike users and advocates all over the world, Pike would hardly be the same either; we are grateful for your commitment.
Who uses pike?
Besides those already mentioned (Roxen IS and SaS, IDA, LiU), there are many other people scattered throughout the world who have put Pike to good use. Read some of their testimonials and find out more about how they value Pike.
…and for what?
Roxen Internet Software wrote the free web servers Spinner, Roxen Challenger and Roxen WebServer in Pike, as well as the highly appraised commercial content management system Roxen Platform / Roxen CMS. SaS uses Pike for their research, currently concentrated on the field of compositioning technology and language connectors. Other noteworthy applications include the works of Per Hedbor, who among other things has written AIDO, a nifty network aware peer-to-peer client/server media player and a distributed jukebox system, both in Pike.
Why use pike?
Pike is Powerful – Being a high-level language, Pike gives you concise, modular code, automatic memory management, flexible and efficient data types, transparent bignum support, a powerful type system, exception handling and quick iterative development cycles, alleviating the need for compiling and linking code before you can run it; on-the-fly modifications are milliseconds away from being put to practice.
Pike is Fast – Most of the time critical parts of Pike are heavily optimized; Pike is really, really fast and uses efficient, carefully handcrafted algorithms and data types. Visit The Computer Language Shootout Benchmarks for more facts and figures on Pike’s performance.
Pike is Extendable – with modules written in C for speed or Pike for brevity. Pike supports multiple inheritance and most other constructs you would demand from a modern programming language.
Pike is Scalable – as useful for small scripts as for bigger and more complex applications. Where some other scripting languages aim for providing unreadable language constructs for minimal code size, Pike aims for a small orthogonal set of readable language elements that encourage good habits and improve maintainability.
Pike is Portable – Platform independence has always been our aim with Pike, and it compiles on most flavors of Unix, as well as on Windows (both ia32 and ia64 versions) and Mac OS X. To see the present status of how well the stable and development branches of Pike work on some of the many hardware architectures and operating systems Pike supports, visit the pikefarm pages.
Pike is Free – Pike is released under multiple licenses; the GNU licenses GPL and LGPL, as well as the Mozilla license, MPL.
Paradigms – Pike supports most programming paradigms, including (but not limited to) object orientation, functional programming, aspect orientation and imperative programming.
Pike is Constantly Improving – While already being a great language, Pike is actively developed and backed by both an active Pike community and the computer science scientific research community. This means that Pike will stay the razorsharp tool that Pike people over the world expect it to be, while assimilating recent findings from the scientific forefront of research, spanning fields such as compositioning, regexp technology and the world of ontologies, also known as the Semantic Web.
Pike is available via git – To help you get your hands on the very latest development versions of Pike, we provide Pike to anyone and everyone who knows his/her way around git. Stay as updated as you like on recent activity in the repository with our on-site repository browser.
You Too are Invited – We welcome contributions to pike, and it is our intention to provide write access to our repositories for those of you who want to join us in improving Pike, be it by contributing code, documentation, work with the web site or making tools and applications of general interest.
Example:
int main() {
write("Hello world!\n");
return 0;
}Pike Resources
Documentation and other resources about the project can be found on the official website of Pike.
Installing Pike
Pike can be installed in the debian based distro’s by running the command
sudo apt-get install pike
Feel free to explore more about this programming language.
(source: http://pike.lysator.liu.se/)
Suggestions for improvements are welcomed.
Checkout the FOSSASIA Idea’s page for more information on projects supported by FOSSASIA.


























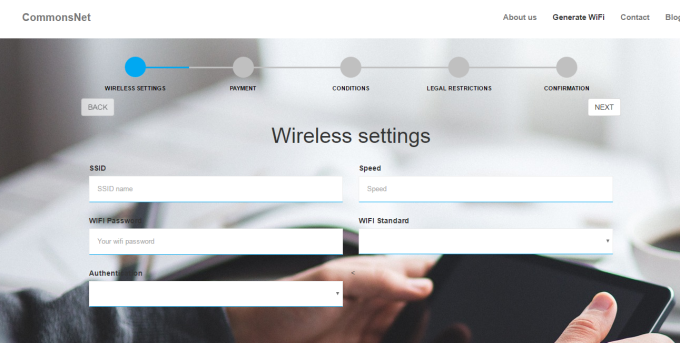

You must be logged in to post a comment.