We in FOSSASIA’s Open Event Server project, allow the organizer, co-organizer and the admins to export all the data related to an event in the form of an archive of JSON files. This way the data can be reused in some other place for various different purposes. The basic workflow is something like this:
- Send a POST request in the /events/{event_id}/export/json with a payload containing whether you require the various media files.
- The POST request starts a celery task in the background to start extracting data related to event and jsonifying them
- The celery task url is returned as a response. Sending a GET request to this url gives the status of the task. If the status is either FAILED or SUCCESS then there is the corresponding error message or the result.
- Separate JSON files for events, speakers, sessions, micro-locations, tracks, session types and custom forms are created.
- All this files are then archived and the zip is then served on the endpoint /events/{event_id}/exports/{path}
- Sending a GET request to the above mentioned endpoint downloads a zip containing all the data related to the endpoint.
Let’s dive into each of these points one-by-one
POST request ( /events/{event_id}/export/json)
For making a POST request you firstly need a JWT authentication like most of the other API endpoints. You need to send a payload containing the settings for whether you want the media files related with the event to be downloaded along with the JSON files. An example payload looks like this:
{
"image": true,
"video": true,
"document": true,
"audio": true
}
def export_event(event_id):
from helpers.tasks import export_event_task
settings = EXPORT_SETTING
settings['image'] = request.json.get('image', False)
settings['video'] = request.json.get('video', False)
settings['document'] = request.json.get('document', False)
settings['audio'] = request.json.get('audio', False)
# queue task
task = export_event_task.delay(
current_identity.email, event_id, settings)
# create Job
create_export_job(task.id, event_id)
# in case of testing
if current_app.config.get('CELERY_ALWAYS_EAGER'):
# send_export_mail(event_id, task.get())
TASK_RESULTS[task.id] = {
'result': task.get(),
'state': task.state
}
return jsonify(
task_url=url_for('tasks.celery_task', task_id=task.id)
)
Taking the settings about the media files and the event id, we pass them as parameter to the export event celery task and queue up the task. We then create an entry in the database with the task url and the event id and the user who triggered the export to keep a record of the activity. After that we return as response the url for the celery task to the user.
If the celery task is still underway it show a response with ‘state’:’WAITING’. Once, the task is completed, the value of ‘state’ is either ‘FAILED’ or ‘SUCCESS’. If it is SUCCESS it returns the result of the task, in this case the download url for the zip.
Celery Task to Export Event
Exporting an event is a very time consuming process and we don’t want that this process to come in the way of user interaction with other services. So we needed to use a queueing system that would queue the tasks and execute them in the background with disturbing the main worker from executing the other user requests. We have used celery to queue tasks in the background and execute them without disturbing the other user requests.
We have created a celery task namely “export.event” which calls the event_export_task_base() which in turn calls the export_event_json() where all the jsonification process is carried out. To start the celery task all we do is export_event_task.delay(event_id, settings) and it return a celery task object with a task id that can be used to check the status of the task.
@celery.task(base=RequestContextTask, name='export.event', bind=True)
def export_event_task(self, email, event_id, settings):
event = safe_query(db, Event, 'id', event_id, 'event_id')
try:
logging.info('Exporting started')
path = event_export_task_base(event_id, settings)
# task_id = self.request.id.__str__() # str(async result)
download_url = path
result = {
'download_url': download_url
}
logging.info('Exporting done.. sending email')
send_export_mail(email=email, event_name=event.name, download_url=download_url)
except Exception as e:
print(traceback.format_exc())
result = {'__error': True, 'result': str(e)}
logging.info('Error in exporting.. sending email')
send_export_mail(email=email, event_name=event.name, error_text=str(e))
return result
After exporting a path to the export zip is returned. We then get the downloading endpoint and return it as the result of the celery task. In case there is an error in the celery task, we print an entire traceback in the celery worker and return the error as a result.
Make the Exported Zip Ready
We have a separate export_helpers.py file in the helpers module of API for performing various tasks related to exporting all the data of the event. The most important function in this file is the export_event_json(). This file accepts the event_id and the settings dictionary. In the export helpers we have global constant dictionaries which contain the order in which the fields are to appear in the JSON files created while exporting.
Firstly, we create the directory for storing the exported JSON and finally the archive of all the JSON files. Then we have a global dictionary named EXPORTS which contains all the tables and their corresponding Models which we want to extract from the database and store as JSON. From the EXPORTS dict we get the Model names. We use this Models to make queries with the given event_id and retrieve the data from the database. After retrieving data, we use another helper function named _order_json which jsonifies the sqlalchemy data in the order that is mentioned in the dictionary. After this we download the media data, i.e. the slides, images, videos etc. related to that particular Model depending on the settings.
def export_event_json(event_id, settings):
"""
Exports the event as a zip on the server and return its path
"""
# make directory
exports_dir = app.config['BASE_DIR'] + '/static/uploads/exports/'
if not os.path.isdir(exports_dir):
os.mkdir(exports_dir)
dir_path = exports_dir + 'event%d' % int(event_id)
if os.path.isdir(dir_path):
shutil.rmtree(dir_path, ignore_errors=True)
os.mkdir(dir_path)
# save to directory
for e in EXPORTS:
if e[0] == 'event':
query_obj = db.session.query(e[1]).filter(
e[1].id == event_id).first()
data = _order_json(dict(query_obj.__dict__), e)
_download_media(data, 'event', dir_path, settings)
else:
query_objs = db.session.query(e[1]).filter(
e[1].event_id == event_id).all()
data = [_order_json(dict(query_obj.__dict__), e) for query_obj in query_objs]
for count in range(len(data)):
data[count] = _order_json(data[count], e)
_download_media(data[count], e[0], dir_path, settings)
data_str = json.dumps(data, indent=4, ensure_ascii=False).encode('utf-8')
fp = open(dir_path + '/' + e[0], 'w')
fp.write(data_str)
fp.close()
# add meta
data_str = json.dumps(
_generate_meta(), sort_keys=True,
indent=4, ensure_ascii=False
).encode('utf-8')
fp = open(dir_path + '/meta', 'w')
fp.write(data_str)
fp.close()
# make zip
shutil.make_archive(dir_path, 'zip', dir_path)
dir_path = dir_path + ".zip"
storage_path = UPLOAD_PATHS['exports']['zip'].format(
event_id=event_id
)
uploaded_file = UploadedFile(dir_path, dir_path.rsplit('/', 1)[1])
storage_url = upload(uploaded_file, storage_path)
return storage_url
After we receive the json data from the _order_json() function, we create a dump of the json using json.dumps with an indentation of 4 spaces and utf-8 encoding. Then we save this dump in a file named according to the model from which the data was retrieved. This process is repeated for all the models that are mentioned in the EXPORTS dictionary. After all the JSON files are created and all the media is downloaded, we make a zip of the folder.
To do this we use shutil.make_archive. It creates a zip and uploads the zip to the storage service used by the server such as S3, google storage, etc. and returns the url for the zip through which it can be accessed.
Apart from this function, the other major function in this file is to create an export job entry in the database so that we can keep a track about which used started a task related to which event and help us in debugging and security purposes.
Downloading the Zip File
After the exporting is completed, if you send a GET request to the task url, you get a response similar to this:
{
"result": {
"download_url": "http://localhost:5000/static/media/exports/1/zip/OGpMM0w2RH/event1.zip"
},
"state": "SUCCESS"
}
So on opening the download url in the browser or using any other tool, you can download the zip file.
One big question however remains is, all the workflow is okay but how do you understand after sending the POST request, that the task is completed and ready to be downloaded? One way of solving this problem is a technique known as polling. In polling what we do is we send a GET request repeatedly after every fixed interval of time. So, what we do is from the POST request we get the url for the export task. You keep polling this task url until the state is either “FAILED” or “SUCCESS”. If it is a SUCCESS you append the download url somewhere in your website which can then clicked to download the archived export of the event.
Reference:










 The PSLab device has three pins dedicated to function as programmable voltage sources (PVS) and one pin for programmable current source (PCS).
The PSLab device has three pins dedicated to function as programmable voltage sources (PVS) and one pin for programmable current source (PCS).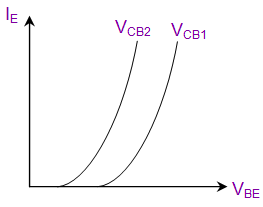
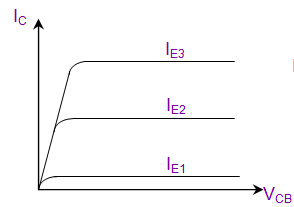
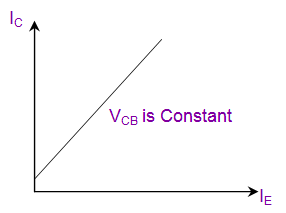
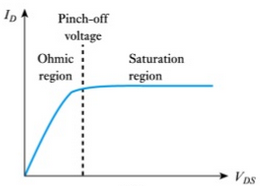
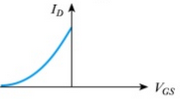
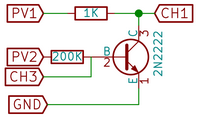 In the following schematic; the collector current can be calculated using known PV1 value and the measured CH1 value as follows;
In the following schematic; the collector current can be calculated using known PV1 value and the measured CH1 value as follows;

You must be logged in to post a comment.