

Query server helps one to scrap search engines like Google, Yahoo, Bing, DuckDuckGo and get the results in json/ xml format. Also it stores retrieved results in mongoDB for analytical purposes.We have used beautiful soup for scraping results from query server
We have used beautiful soup for scraping results from query server
In this blogpost I will discuss two recent implementations in query server and then end with the introduction of different scrappers for query server.
Implementation of teaser text for Google, Yahoo, and DuckDuckgo:
Teaser text is basically description that is provided by search engines for all search results, this could be implemented by scrapping the description of each result and push it into a list. This is done in query server using beautiful.
Implementation details of this feature is available at pull:
https://github.com/fossasia/query-server/pull/72
And finally we have achieved scaping teaser text for all supported search engines:
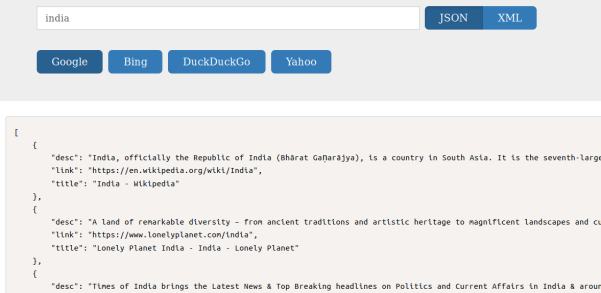
Implementation of Image scraper for google in query server:
Scapping images in google is a bit different from scrapping normal text results. Google has metadata of the original image in rg_meta tag of div containing the thumbnail of the image. We cannot scrap just the thumbnail, because thumbnails are basically of low quality, and also are stored in google server, whereas the links available in the meta data are from the original source. Finally using the metadata of images available we have scraped the images in google.
Implementation details of image scraper to google is available at https://github.com/fossasia/query-server/pull/73

Also we have separated one scraper file for each of the search engine using Object Oriented Paradigm, where as before we used to have only one scraper file for all search engines https://github.com/fossasia/query-server/pull/67
Resources
BeautifulSoup: https://www.crummy.com/software/BeautifulSoup/bs4/doc/