

How SUSI Analyzes A Given Response
Ever wondered where SUSI’s answers come from? Now Susi has ability to do an answer analysis. To get that analysis, just ask susi “analysis”. This will set susi into an analysis mode, will tell where the latest answer came from and will give you the link for improving the skill.
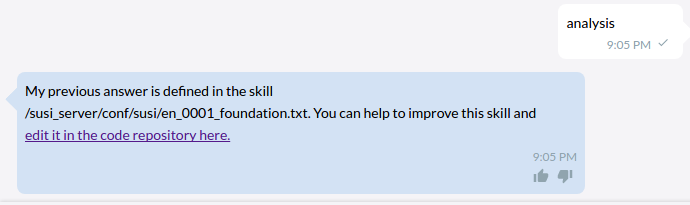
Let’s check out how Susi analysis work. The skill for analysis is defined en_0001_foundation.txt as following
analysis|analyse|analyze|* analysis|* analyse|* analyze|analysis *|analyse *|analyze * My previous answer is defined in the skill $skill$. You can help to improve this skill and <a href="$skill_link$" target="_blank"> edit it in the code repository here.</a>
$skill$ and $skill_link$ are the variable compiled using
public static final Pattern variable_pattern = Pattern.compile("\\$.*?\\$");
These variables are memorized in Susi cognition. A cognition is the combination of a query of a user with the response of susi.
SusiThought dispute = new SusiThought(); List<String> skills = clonedThought.getSkills(); if (skills.size() > 0) { dispute.addObservation("skill", skills.get(0)); dispute.addObservation("skill_link",getSkillLink(skills.get(0))); }
Susi Thought is a piece of data that can be remembered. The structure of the thought is modeled as a table in which information contained in it is organized in rows and columns.
public SusiThought addObservation(String featureName, String observation) ;
One can memorize using addObservation() method. It takes two parameter featureName the object key and observation the object value. It is a table of information pieces as a set of rows which all have the same column names. It inserts the new data always in front of existing similar data rather than overwriting them.
public String getSkillLink(String skillPath) { String link=skillPath; if(skillPath.startsWith("/susi_server")) { link ="https://github.com/fossasia/susi_server/blob/development" + skillPath.substring("/susi_server".length()); } else if (skillPath.startsWith("/susi_skill_data")) { link = "https://github.com/fossasia/susi_skill_data/blob/master" + skillPath.substring("/susi_skill_data".length()); } return link; }
The getSkillLink is a utitlity method to return the link of the skill source github repository based on skillPath.
private String skill; SusiThought recall; final SusiArgument flow = new SusiArgument().think(recall); this.skill = origin.getAbsolutePath(); if (this.skill != null && this.skill.length() > 0) flow.addSkill(this.skill);
The source of the skill gets added in SusiIntent.java using getAbsolutePath() method which resolves the skill path in the filesystem. Intent considers the key from the user query, matches the intent tokens to get the optimum result and produces json like
"data": [ { "object": "If you spend too much time thinking about a thing, you'll never get it done.", "0": "tell me a quote", "token_original": "quote", "token_canonical": "quote", "token_categorized": "quote", "timezoneOffset": "-330", "answer": "When you discover your mission, you will feel its demand. It will fill you with enthusiasm and a burning desire to get to work on it. ", "skill_link": "https://github.com/fossasia/susi_skill_data/blob/master/models/general/entertainment/en/quotes.txt", "query": "tell me a quote", "skill": "/susi_skill_data/models/general/entertainment/en/quotes.txt" },
The getskills() method returns list of skill from json which are later added for memorization.
public List<String> getSkills() { List<String> skills = new ArrayList<>(); getSkillsJSON().forEach(skill -> skills.add((String) skill)); return skills; }
This is how Susi is able to fetch where the answer came from. Next time when you have a chat with susi do check skill analysis and add your ideas to improve the skill. Take a look at Susi_skill_data for more skills and read this tutorial for creating skills for susi.
Resources
- Teach Susi a skill https://blog.fossasia.org/how-to-teach-susi-skills-calling-an-external-api/
- A developer’s guide to chatbots by Michael Yuan https://www.ibm.com/developerworks/library/cc-cognitive-chatbot-guide/index.html
- Building a Chatbot: analysis- by Javier Couto https://tryolabs.com/blog/2017/01/25/building-a-chatbot-analysis–limitations-of-modern-platforms/
- The source code – https://github.com/fossasia/susi_server/tree/development/src/ai/susi/mindSusi
- Skill Development tutorial- https://github.com/fossasia/susi_skill_data/blob/master/README_susi_skill_language_tutorial.md





























You must be logged in to post a comment.