

Crawl Job Feature For Susper To Index Websites
The Yacy backend provides search results for Susper using a web crawler (or) spider to crawl and index data from the internet. They also require some minimum input from the user.
As stated by Michael Christen (@Orbiter) “a web index is created by loading a lot of web pages first, then parsing the content and placing the result into a search index. The question is: how to get a large list of URLs? This is solved by a crawler: we start with a single web page, extract all links, then load these links and go on. The root of such a process is the ‘Crawl Start’.”
Yacy has a web crawler module that can be accessed from here: http://yacy.searchlab.eu/CrawlStartExpert.html. As we would like to have a fully supported front end for Yacy, we also introduced a crawler in Susper. Using crawler one could tell Yacy what process to do and how to crawl a URL to index search results on Yacy server. To support the indexing of web pages with the help of Yacy server, we had implemented a ‘Crawl Job’ feature in Susper.
1)Visit http://susper.com/crawlstartexpert and give information regarding the sites you want Susper to crawl.Currently, the crawler accepts an input of URLs or a file containing URLs. You could customise crawling process by tweaking crawl parameters like crawling depth, maximum pages per domain, filters, excluding media etc.

2) Once crawl parameters are set, click on ‘Start New Crawl Job’ to start the crawling process. 
3) It will raise a basic authentication pop-up. After filling, the user will receive a success alert and will be redirected back to home page.
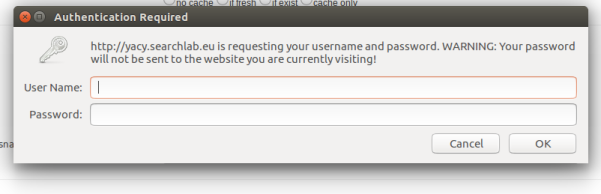
The process of crawl job on Yacy server will get started according to crawling parameters.
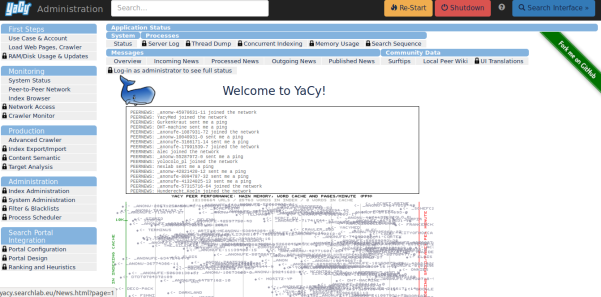
Implementation of Crawler on Susper:
We have created a separate component and service in Susper for Crawler

Source code can be found at:
- https://github.com/fossasia/susper.com/blob/master/src/app/crawlstart/crawlstart.component.ts
- https://github.com/fossasia/susper.com/blob/master/src/app/crawlstart.service.ts
When the user initiates the crawl job by pressing the start button, it calls startCrawlJob() function from the component and this indeed calls the CrawlStart service.We send crawlvalues to the service and subscribe, to the return object confirming whether the crawl job has started or not.
crawlstart.component.ts:-
startCrawlJob() { this.crawlstartservice.startCrawlJob(this.crawlvalues).subscribe(res => { alert('Started Crawl Job'); this.router.navigate(['/']); }, (err) => { if (err === 'Unauthorized') { alert("Authentication Error"); } }); };
After calling startCrawlJob() function from the service file, the service file creates a URLSearchParams object to create parameters for each key in input and send it to Yacy server through JSONP request.
crawlstart.service.ts
startCrawlJob(crawlvalues) { let params = new URLSearchParams(); for (let key in crawlvalues) { if (crawlvalues.hasOwnProperty(key)) { params.set(key, crawlvalues[key]); } } params.set('callback', 'JSONP_CALLBACK'); let options = new RequestOptions({ search: params }); return this.jsonp .get('http://yacy.searchlab.eu/Crawler_p.json', options).map(res => { res.json(); }); }
Resources:
- Endpoint API for Yacy: http://yacy.searchlab.eu/Crawler_p.json
- Documentation of Yacy API Endpoint: http://www.yacy-websearch.net/wiki/index.php/Dev:APICrawler












 Search box on Firefox
Search box on Firefox



You must be logged in to post a comment.